Why I Chose the AI Memory Problem
The moment I realized AI memory would be used against us (and why user control is the only path forward)

I was six months into building the predecessor to Ask Safely when I hit a wall I didn’t expect.
We needed a trustworthy AI backbone. The whole product depended on it. Whatever model/API we chose, our users would be trusting it with sensitive information. So I went deep into the policies.
ChatGPT’s terms were vague and broad. Intentionally misleading (in my opinion). Perplexity’s CEO had publicly disclosed their vision to collect data on everything users do online to serve “hyper personalized” ads (they’ve since walked this back – much respect). OpenAI kept taking vast sums of money while offering free AI to more and more people. Someone had to pay for that. I knew who.
Claude was the closest thing to trustworthy. Then in August 2025, Anthropic shifted to training on user data by default (with the toggle pre-checked to “on”) and extended retention to five years for those who didn’t opt out. It’s the cheapest way to train models and they felt the need to stay competitive (it seems to have worked).

** Note: Ask Safely accesses Anthropic models via AWS Bedrock’s enterprise grade API with model training turned OFF by default. We found this was the best way to assure privacy while using the best models.
With that, I couldn’t find one I could fully trust out of the box. Open source models weren’t reliable enough for what we needed (still aren’t). And nobody wants the complexity of managing their own hardware. So there I was: stuck, realizing that the entire AI industry was heading down a path I’d been worried about for nearly a decade.
That’s when the full picture clicked.
The thesis I’d been carrying since 2015
Back in 2015, I went deep on how Google and Meta actually make money. Surveillance-based advertising. They extract user data, build profiles you never see, and monetize your attention. Around the same time, Dollar Shave Club went viral selling razors for a fraction of what Gillette charged. The insight that stuck with me: if Dollar Shave Club could disrupt “margin-fat” incumbents, Google and Meta would eventually face similar disruption when their business models got too bloated. Too extractive. Too much guessing. Too inefficient.
For nine years, I researched what that disruption might look like. Self-sovereign identity. Privacy-preserving technology. Even blockchain. Ways for regular people to control their own data (and eventually benefit from it instead of handing it over for free to platforms that monetize it against them).
I always imagined those shadow profiles. Google and Meta had built psychological models of me that I had no input into. No ability to correct. No way to see. It felt like blatant disrespect. Undeserving of trust for services becoming so intimately involved in our lives. Like a friend who keeps the receipts and shows them out of context to others behind your back.
AI memory is that same problem, but worse.
Why AI memory raises the stakes
AI conversations take this risk to a different level: we talk to chatbots like confidants. We ask questions we’d never type into Google. We share doubts, fears, health concerns, relationship problems. We think out loud.
When AI memory works well, the user gets maximum value. The AI knows your context. It remembers your preferences. It builds on past conversations instead of starting from scratch every time. When it goes wrong, you’re exposed to maximum risk.
I experienced this firsthand. After we tweaked Ask Safely’s strategy (from family AI safety broadly to AI memory profiles specifically), Claude kept steering me toward “families & teens” in every conversation. It was stuck on an old version of me. Hours of wasted effort because it couldn’t let go of context that was no longer relevant. I had to start working exclusively in projects filled with the freshest data to get it working again. Super annoying. But the deeper problem is what happens when the memory isn’t yours to control.
What’s already happening
Last year, security researchers discovered that ChatGPT was building detailed profiles of users that went far beyond the visible “Manage Memory” settings. By using specific prompts to dump raw data, they found psychological assessments and behavioral tags that weren’t visible in the normal interface. The hidden profile contained verbose personality inferences and confidence scores. A key issue arises with this implementation.
Often times, irrelevant context bleeds across conversations because the AI cannot appropriately contextualize the information when it was shared. Maybe the idea came from a friend, colleague or in the below case, a client and it continues to be used as a core memory about you.

Additionally, users reported fake memories the AI invented (things they never said) likely attributed to the synthesis that occurs in the black-box memory capability to fill knowledge gaps.

This leads to ChatGPT’s deletion in a nutshell: when you delete a conversation, the chat is scheduled for removal within 30 days. As we know, these chats are not exempt from being subpoenaed in a court case and can be used against you. But more concerning is that memory is stored separately.
Delete a chat, and the memory extracted from it still persists and can’t really be changed by the user (only overwritten or even silently deleted by the AI lab’s own aglorithms).. Simon Willison, a well-known developer, called it “effectively collecting a dossier” on users.

What really validated the thesis for me:
In December 2025, Meta announced they would start using conversations with Meta AI to personalize ads across Facebook, Instagram, WhatsApp, and Messenger. A billion monthly users. When you chat with Meta AI about weekend plans, parenting struggles, or major life decisions, those conversations become fair game for advertisers. There’s no opt-out.
The Electronic Privacy Information Center wrote to the FTC that AI chats are “inherently more intimate” than likes and shares, noting that “conversational data is substantially more sensitive than ordinary behavioral data” because it “may reveal personal relationships, mental health concerns, political views, and other intimate information.”
Where this goes
We’ve already seen the pattern with social media. A former Facebook policy director revealed that the platform detected when teenage girls deleted selfies (a signal of insecurity) and immediately served them beauty ads. Cambridge Analytica systematically targeted voters based on personality profiles built from Facebook data. The key finding from investigators: targeting that “plays to the fears and the prejudices of people” is “more invasive than obviously false information.”
That was with behavioral data (likes, clicks, follows). Now imagine what’s possible with your private conversations.
You chat with AI about a fear you have. It shows up a few times in your feed (content that amplifies that fear). Then an ad appears with a product that “solves” the problem. That’s psychological manipulation to create a buying decision on unfair terms. And that’s just the commercial application. The same mechanics could shape beliefs, political views, life decisions. The trajectory leads somewhere I don’t want to see: people heavily influenced by AI, while thinking they’re in control of it.
No one is immune
It’s tempting to think this is only a problem for kids or vulnerable populations. And yes, the risks are especially acute for them. Children will grow up talking to AI like a friend, sharing things they might not share with parents. It’s a breach of freedom for companies to leverage that vulnerability.
But neurotypical adults are not exempt. Cambridge Analytica didn’t just target the easily manipulated. They targeted everyone, tailoring messages to each personality type. The deleted-selfie-to-beauty-ad pipeline worked because insecurity is universal, not exceptional.
We all have moments of doubt. Moments when we’re tired, stressed, or uncertain. Those are exactly the moments when we turn to AI for help. And those are exactly the moments that create the most valuable targeting data. The professionals reading this newsletter (smart, accomplished, skeptical) are not immune to influence when it’s personalized to their specific psychology and delivered at moments of uncertainty. That’s not a weakness. That’s being human.
What user-controlled memory actually looks like
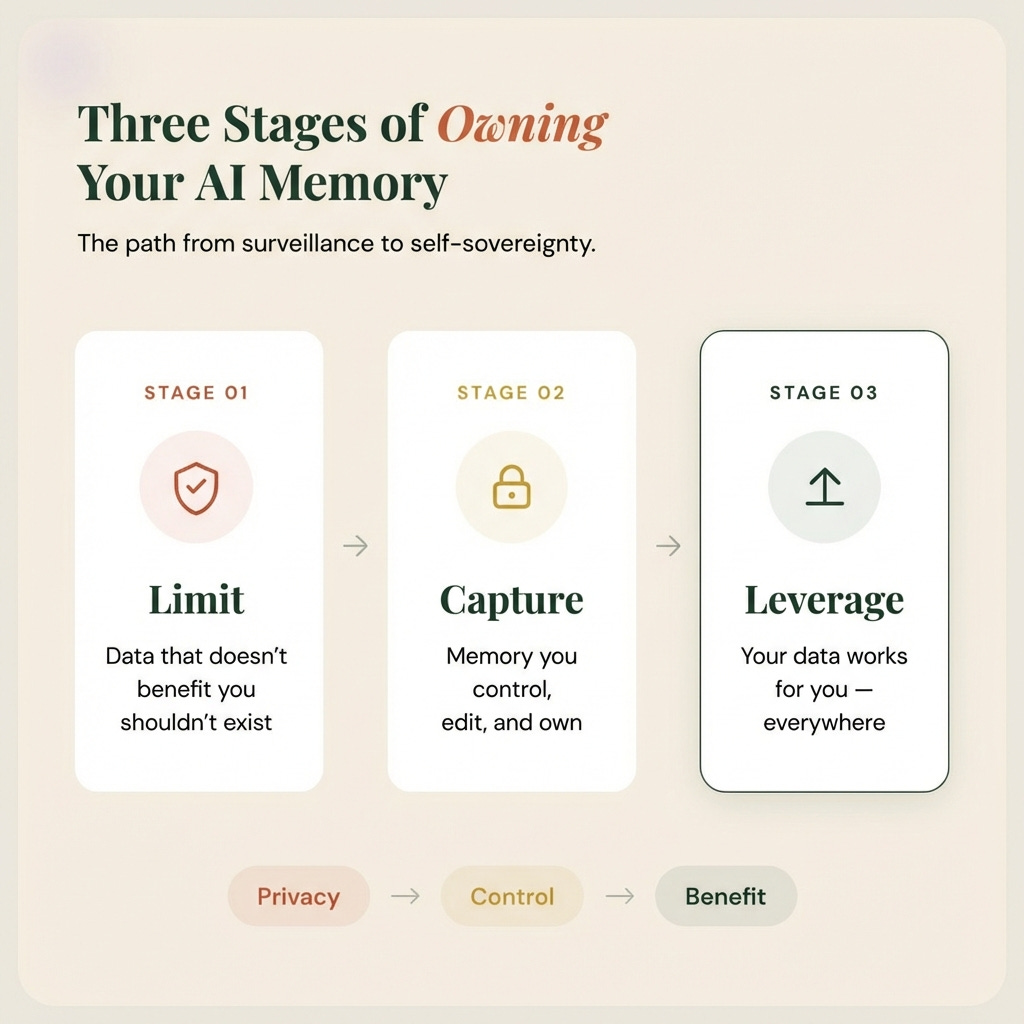
I’ve come to think about this in three stages.
Stage one: Limit unnecessary data sharing. If data doesn’t benefit you directly, it shouldn’t exist. That’s why Ask Safely auto-deletes conversations. Your chat history disappears in 8 hours. The AI can’t build a permanent dossier because there’s nothing to build it from.
Stage two: Capture information that’s high value for your specific needs. Memory isn’t inherently bad. A basic memory profile (the things you actually want the AI to remember) should be something you control, edit, and own. You decide what goes in. You decide (and see exactly) what comes out.
Stage three: Leverage that data to benefit your life. Better, personalized AI that works for you. Portability (your memory profile travels with you, not locked into one platform). Eventually, using your own data to get incredible products, deals & services in the marketplace of the future. The value flows to you, not extracted from you.
Privacy is the foundation. Control is the mechanism. Efficiency and time savings is the outcome.
Why I care enough to build this
My daughter will grow up in a world where AI is everywhere. She’ll talk to it like a friend. She’ll share things with it that she might not share with us.
The big AI labs are moving fast. Their valuations are outrageous. Their infrastructure costs are astronomical. They need to extract maximum value from users to justify what they’ve raised. They’re surveillance-based business models are defined. That pressure shapes every product decision they make.
I want there to be another option. An AI that works for you, forgets what you want forgotten, and keeps what you want kept. Under your control. For your benefit. That’s the problem I chose. That’s why I’m building Ask Safely.
For those considering their own leap
If you’re reading The Second Build, you’re probably circling a problem of your own. Here’s what I’ve learned: the problem has to feel personal enough that you’ll work on it for years, but universal enough that others will pay you to solve it. I spent nine years circling this problem before I wrote a line of code. That wasn’t wasted time.
But what if you don’t have that conviction yet? Paul Graham’s advice: get certainty by working on things you’re interested in. You don’t need a job doing X to work on X. Start now, in some form, and the conviction might come from doing (not planning).
The clear problem will emerge for you, just like it did for me after getting into the solution.
---
Have you had a creepy AI memory moment? Something it “remembered” wrong, or something it surfaced that made you pause? I’m collecting these stories. Hit reply. I read every response.